Recent
May 5, 2026
The WTF agent sessions
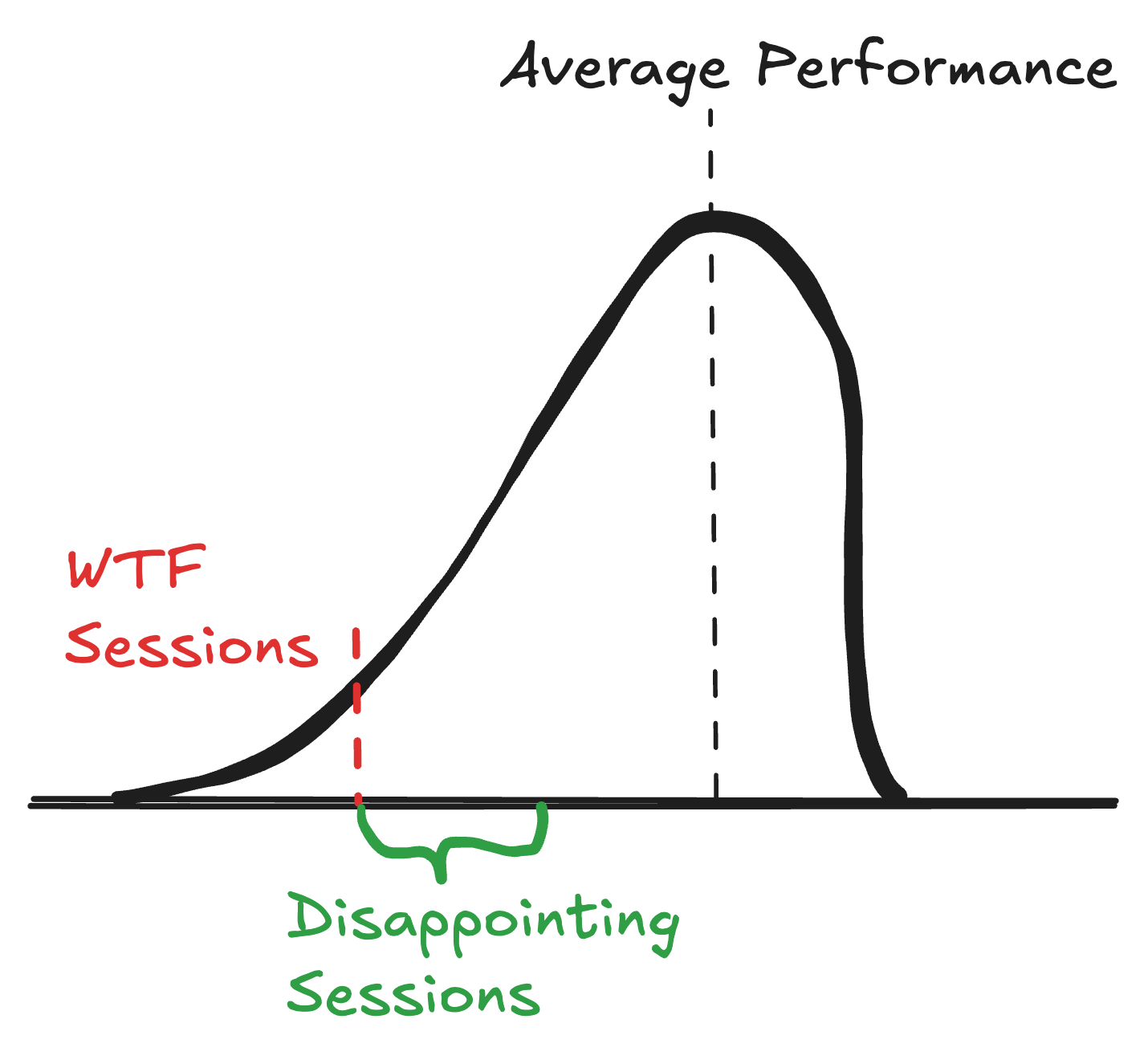
This is my mental model of coding agent sessions these days. Most runs are pretty good. Some are great. Some are disappointing. But a small tail of them just go off the deep end. They’re not *duds*, they just get fixated on some small piece of info that every other agent breezes over and that detail throws them into a crazy rabbit hole.
[... 165 words]April 3, 2026
The Hidden Cost of Fewer Tokens: Context efficiency makes Playwright CLI slower
A blog post I wrote for the work tech blog about some surprising experiment results when I swapped the Playwright CLI in for the MCP. https://outpost.ranger.net/post/the-hidden-cost-of-fewer-tokens/
March 12, 2026
Killed (and Surprised!) By a Traffic Engineer
I recently read Killed by a Traffic Engineer by Wes Marshall.
[... 1,286 words]Jan. 14, 2026
It is simply impossible not to see the reality of what is happening. Writing code is no longer needed for the most part. It is now a lot more interesting to understand what to do, and how to do it (and, about this second part, LLMs are great partners, too). It does not matter if AI companies will not be able to get their money back and the stock market will crash. All that is irrelevant, in the long run. It does not matter if this or the other CEO of some unicorn is telling you something that is off putting, or absurd. Programming changed forever, anyway.
— Salvatore Sanfilippo, Don't fall into the anti-AI hype
Jan. 12, 2026
Look at all those tiny threads! Look at the token counts, and the number of user messages sent. The biggest thread is 151k output tokens and four user messages. The average thread is around 80k tokens. Now think of the time when we had a 1 million token context window. I wouldn’t run a thread that long…
But hey, there are 13 threads in that feature. Probably more, as these are only the threads connected by thread mentions. Add up all those and you’re close to one jam-packed 1 million token context window.
...
I start with a thread to build a basic implementation. If I think it’s going to be complicated, I might start with a thread to investigate some area of the codebase and gather the required context.
From that base, I’ll start new threads to tweak or refactor. Each change is a new thread — one change per thread. I use the read_thread tool to gather needed context from either the initial thread or from the previous refactor/tweak thread.
I'm thinking about how to integrate this approach into my workflow. I've recently wound up working with a lot of mega-conversations in Claude Code. Hours or days long, several compactions, and enough context that it feels like a huge pain to start over.
Clearly, that's not ideal, for model functioning or anything else.
I like the amp concept of read_thread as a tool -- curious if anyone has implemented something similar for Claude. Obviously the .jsonl files are there, so it should be possible.

A lot of things about software engineering are changing very, very quickly. Three years ago, ChatGPT could write you a probably-buggy script. Two years ago, it could pretty effectively regurgitate stack overflow in a specific domain. A year ago, it could write a medium sized amount of code, but probably miss a lot of nuance and write tests that said an obfuscated version of
return true.Skepticism was warranted. Cautioning that there was a lot of hype and that it created ai slop was deserved. Eye-rolling about unmaintainable "vibe coding" was reasonable.
And then things started to change. AI isn't replacing software engineers right now. But it should be changing how they work and how they think about their work. That is both undeniable and non-reversible.